
Source code repositories using tools like Git, Subversion or Mercurial are essential to any modern software project and it is important that they are efficiently organised. We recently merged multiple repositories into a single codebase and found it gave us significant efficiency gains. In this article, we take a step back and look at how we should architect our repositories - when we should merge, and when we should draw apart.
How we got to this
On a recent project, we were working with four source code repositories:
- UI
- API
- Ansible playbook
- Release tool
Having them being separate was causing us three points of pain:
Pain point 1: branch management
We had to keep branches in check across repositories. So, if I created a branch for FEATURE-A, and it had UI and API changes, I had to have a branch in each repo named exactly the same.
Pain point 2: difficulty of review
Multiple pull requests had to be raised for any user stories which touched more than one part of the system. This led to us having to list dependencies for any given pull request. Therefore, if one pull request for a feature was merged but its dependency was not, the system would be in an inconsistent state.
Pain point 3: difficulty of automation
We had to do some gymnastics with our automated demo branch deployment. For example:
UI change detected in branch FEATURE-A
Is there a corresponding API branch FEATURE-A?
YES
Deploy UI FEATURE-A and API FEATURE-A
NO
Deploy UI FEATURE-A and API MASTER
It meant, for example, that any changes to our Ansible playbook, which handles all our deployment/provisioning and infrastructure, were not tied to the corresponding API or UI code, so if a given feature branch required a different package to be installed via Apt, for example, we had to switch the Ansible branch on Jenkins. Not an elegant solution!
This also led to potential race conditions, whereby multiple builds could kick off together due to pushes to two repos just four seconds apart:
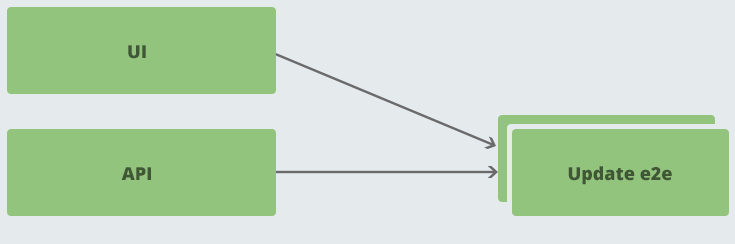
This was a problem because e2e was a single environment and we could not test it in parallel, so this meant we had to create a fairly complex build pipeline with dependencies, or to have some kind of quiet period:
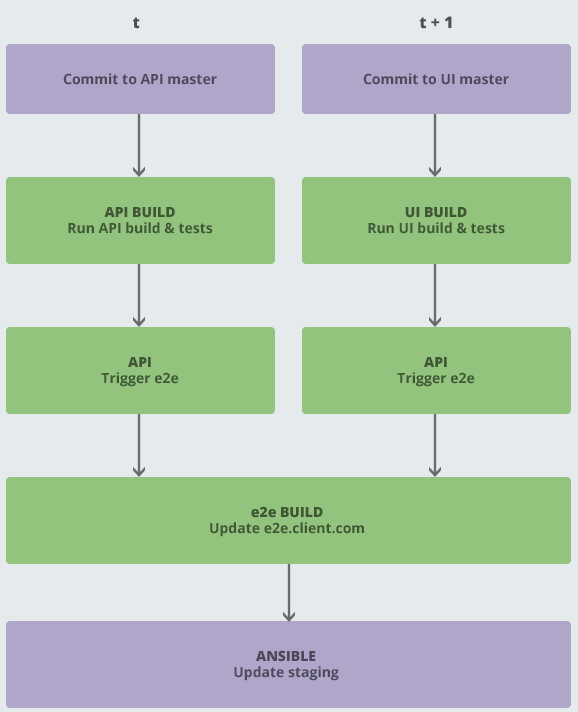
Furthermore, our release tool was pretty baroque - it had to check out all the other 3 repositories, run some checks, prompt for a tag, merge to production and push. It was only 60 or so lines of node.js code, but it had to be maintained and tested regularly, just like anything else.
Tackling it head on
It was abundantly clear that these repositories were linearly related and that our workflow was being made overly complex by our repository layout. We figured that we could make some gains here.
Our approach to process and tooling change loosely follows the scientific method - we only change a single process or tool per sprint, then we look into it in our retrospectives. We had identified these pain points and scheduled in some time to investigate merging the repository.
Once we had merged the repositories into one, we observed three great benefits:
- Easier branch management. One feature, one branch!
- Easier reviews. No dependencies! No need to track multiple pull requests against a single Pivotal Tracker story!
- Simpler, faster, more consistent demo environment deployments. We were able to ditch our release tool entirely and strip out dozens of lines from our Ansible playbooks and Jenkins jobs.
So, in this particular case, we believe we made a good decision to merge our repositories. When is the right time to merge, though? Is it always the answer? Let’s take a step back and look at the general case:
To merge or not to merge? That is the cliché...
It’s very tempting to separate an application into separate repositories, particularly if they are being worked upon by separate teams. By combining, however, we may run the risk of reducing our separation of concerns. What goes together and what goes apart is a really important consideration for software developers, and one that merits a great deal of careful consideration!
Repository smells
A code smell is defined on c2.com as "a hint that something is wrong in your code", and seems to have been coined by Kent Beck. There now exists a whole taxonomy of code smells, which I’d recommend all developers familiarise themselves with. In the light of this, I define a "repository smell" as a similar concept, whereby a repository or multiple repositories of code exhibit similar hints that something is awry.
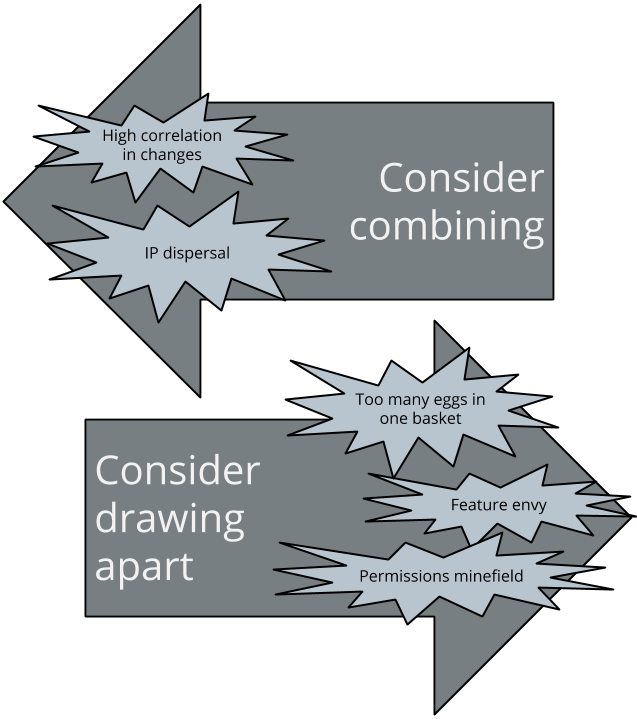
I define five repository smells. Two of them should lead us to consider merging code repositories, the other three should lead us to consider drawing code apart into separate repositories.
Smell 1: High correlation in changes
In our case, there was a linear relation between the number of pull requests in our UI and API libraries. In fact, most commits required PRs to both. It therefore made enormous sense to merge them. I’d define this as there being a strong correlation in changes.
- If components change together and a change to one implies a change to another, consider combining their repositories.
- If you find that you frequently have to make changes in groups across multiple repositories, then perhaps you have a good case for combining them.
Smell 2: Intellectual property dispersal
You may have a client that has an application with multiple facets, which may be in separate repositories. It is often easier to manage permissions for third party access in one repository. Also, you are grouping the intellectual property into one place. Having dispersed intellectual property may increase the likelihood of it ending up somewhere it shouldn't!
- If multiple repositories are the intellectual property of a given client and are closely related, consider combining them together.
Smell 3: Feature envy
Much like the feature envy code smell, in OOP, repositories may seem to be overly interested in code from other repositories. This can result in importing a much larger amount of dependency code than is strictly necessary.
Let’s say, for example, that you have a little tool that your repo uses but you also use it in other projects, and you’re checking out the whole project every time just for this one tool.
- If you find that an entire repository is checked out just for one small self-contained module, then you likely have a case for it being in its own repository.
If a project is a standalone tool, for instance, I generally advocate having a separate repo with its own documentation, tests and so forth. That way, it’s much better in a “wood for the trees” sense. If a project is a compact, redistributable, standalone tool, then put it in its own repository (and consider open sourcing it as a secondary deliverable).
Smell 4: Too many eggs in one basket
Closely related to code envy, but this is more about looking at the repository as a whole rather than a particular part of it. When areas of a repository are basically unrelated and change at different rates entirely, this may be considered as too many eggs in one basket. For example, you might have multiple tools in one library that aren’t actually related and perform unrelated tasks.
- If you find that one subtree of a repository changes in isolation to the rest of the repository, you may wish to break it out.
Smell 5: Permissions minefield
I once worked for a large organisation that kept all their code in a single repository. This was really taking it too far in my opinion! What that can result in is security issues. You’re essentially either trusting everyone with your entire code tree, or nothing at all, which is not a great degree of granularity! Of course, many tools, such as Subversion, do permit subtree permissions, but this can get scrappy quickly!
- If you find that you are having to manage granular permissions, it might be a sign that you need to break out a repository into multiple different repositories.
Merging git repos
If you'd like to merge your repositories, a good place to start is this article about Git subtree merges.
A Word of Caution
Make sure that you don’t use merging to a single repo as a shortcut to making all your components as self-describing and self contained as possible and managing dependencies correctly. It may be a convenience in some cases, but it can also result in your repository becoming chaotic.
Thanks to package managers like NPM, Composer or Bower, dependency management in 2015 is much less of a nightmare than it used to be. With powerful tools like Git, a bad repository architecture need not be something you need to live with forever.
Wrapping up
As our application was reasonably small, and functioned as a whole, it made a lot of sense to merge it. Sometimes, though, it’s far better to keep things separate, and the guidelines we’ve defined made here should help you to know when.
Have you had success or pain from your repository organisation? Can you think of any repository smells we haven’t thought of? Let us know what you think in the comments section below! If you have an unwieldy software project, perhaps we can help you!
