
Radify recently adopted an immutable infrastructure approach for our web and API nodes. In this article, we talk about what it is, why we did it, and what the costs and benefits have been.
What is immutable infrastructure?
Immutable infrastructure, or an immutable deployment, is where infrastructure never changes - it is simply completely replaced wholesale when a deployment happens. It is an attempt to control the amount and location of state in a system. Instead of the historical pattern of having a group of servers and maintaining them over time, with immutable infrastructure you stand up new servers on every deploy. You then install your application on them, add them to the load balancer, then remove the old ones and destroy them. You can achieve rapid results by having a custom base box, which you provision in advance, so that only your code needs to be deployed.
Why use immutable infrastructure?
I’ll be honest, part of the initial impetus was to be part of the "cool gang". All the other kids are doing it, why not us? Initially, several objections raised themselves. Foremost amongst these was, and I could be wrong, but it seems to me that a lot of the people who talk about immutable infrastructure are fairly large, high traffic, product-based organisations. Was immutable infrastructure out of our reach as a relatively lean agile software consultancy? And is it necessary? Most of our projects are B2B client projects — we’re certainly some way from “Netflix traffic”!
The more we discussed it, however, the more sense it made. We had a strong build pipeline already (described briefly in 4 Principles of DevOps), but we were finding that the packages on our servers were getting out of date. Our projects have at least 5 stages (local development, test/demo, end to end testing, staging and production) and each stage has 1..n nodes – so although we’re not exactly talking Facebook numbers, updating these servers could be a pain. Small example: updating them via apt over Ansible worked okay most of the time, but occasionally servers would require reboots, and we would have had to stagger those… it just became a lot of hassle. Heartbleed was a couple of hours spent patching and testing that we didn’t want to go through again.
There were other issues with having to maintain running nodes. They could get out of sync – if, for example, we stood up a new node and added it to a cluster, perhaps the new node may have a newer version of a given library? This never caused us any problems, but potentially, it could have done. It’s best to have every node in a cluster be utterly identical, otherwise debugging can become non-deterministic.
Immutable infrastructure means that we can simply stand up a new set of nodes every time, and these will be provisioned with the latest packages from the get-go and to have each environment be in a known state, so it seemed to us that it was worth investigating!
Telling the story
I ran some tests and initially a full provisioning of one node for a particular client from a bare bones Ubuntu LTS AMI (Amazon Machine Image) took nearly 15 minutes. This diagram shows a greatly simplified version of this (I haven’t listed everything we install, just some examples):
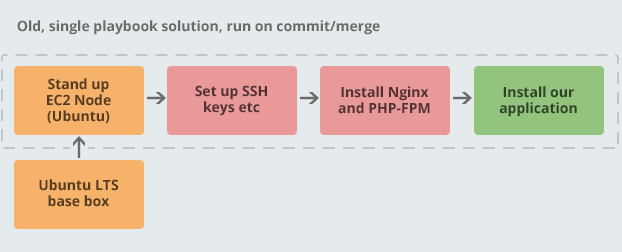
We initially evaluated Packer for this project, but it didn’t really seem to give us anything that our existing tooling wasn’t already giving us. I didn’t like that it used a local Ansible, which installed rather more dependencies than I would have liked. So, we decided to refactor our existing playbook to take out the common stuff that is the same or similar between clients and create a radify-base-box playbook which builds an AMI. We update this AMI nightly to make sure that it’s always ready to go with the latest security fixes and so forth. Then, applying the client’s playbook took only two or three minutes per node. The diagram below shows this:
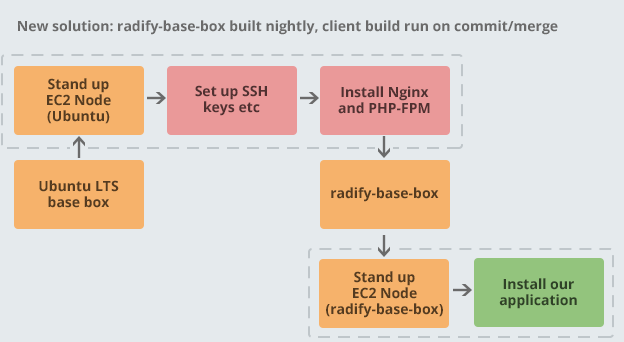
This solved our issue of slow deployments, and also allowed us to have a common base image across similar projects which is consistently configured. If we make some key change, we can even do that cross-project. We are also able to use this base playbook with our Jenkins cluster, which is also provisioned by Ansible, so that we have the very same infrastructure across the board. Pretty nifty!
Benefits and challenges
Benefits
Encourages you to log "off box" - we use PaperTrail for this
Far less time spent babysitting servers. This is the "treat servers like cattle, not like pets" approach. If a server goes nuts, we have its logs, and we can simply burn and replace it immediately with zero downtime.
Insulated from the risk of an external dependency being down. For example, if we install some node modules on our base box, this protects us from NPM having issues. Updating our base box periodically means that even if it’s down for some time, we are not far behind the latest patches.
Prevents the temptation to "hand hack" servers
Boxes are in a known state and have the latest security patches
Disks can’t fill up with logs etc
Consistent infrastructure cross-project
No real change to the cost - unused nodes are destroyed shortly after they are removed from the load balancers.
Massive reduction in the amount of playbook code. Lots of red lines in the pull request! A couple of examples:
The playbook that updated the code but not the environment? Gone!
The playbook that updated the dependencies? Gone!
Challenges
There are various challenges with immutable infrastructure:
Time spent working on automation. I think that this work has great value to Radify as a business, and to our clients, but nothing comes for free. I spent perhaps 3 days setting this up, plus our team’s time reviewing it and several meetings discussing it.
Some people may be uncomfortable with the concept of disposability in services.
Wrapping up
The 12 Factor approach isn’t for everyone - it certainly has its critics - but for us we have found it makes things clean and the moving parts don’t grind together and throw springs all over the place. Adopting immutable infrastructure has been a big step along this road for us.
Not having to worry maintaining nodes has been something of an administrative weight off our collective shoulders. What’s really quite encouraging is that we have been able to do this despite being a fairly small team.
Further reading
To get two very different perspectives on immutable infrastructure, I recommend these three articles:
For: "Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components" - Chad Fowler makes the case for Immutable Infrastructure. Flo from CodeShip also puts the case forward very clearly.
Against: "Immutable Infrastructure: Practical or Not?" - the counter argument from the folks at Chef. It’s always worth trying to understand the other opposing perspective.
So, what do you think? Do you use immutable infrastructure? Would you like to? Do you think it’s a good thing?
