
There are lots of misconceptions about “DevOps”. Some people think it’s a set of tools (e.g. “Puppet is our DevOps tool”). Others think it’s a role in the organisation (e.g. “Charlie does our DevOps”). It’s neither of those things - I suppose I’d describe DevOps as a way of thinking. At Radify, we work from 4 principles:
- Holistic system thinking
- No silos
- Rapid, useful feedback
- Automate drudgery away
In this article, we look at these principles one at a time, demonstrating how they drive our process, tooling and workflow.
Principle 1 of 4: Holistic system thinking
Holistic system thinking simply means thinking about the whole system – in fact, the whole project and the ecosystem around it. It is the opposite of thinking just about “my little bit”.
As a coder, it is often tempting to try to solve all problems with code. Got a problem? Throw code at it until it goes away! For a long time as a developer, my only tool was the sledgehammer of code, even when the nails were actually screws. Or rawl plugs, whatever they are – you get the picture. As I matured and learned from the people around me, I realised that many problems were not, in fact, code problems at all.
Defining the problem space
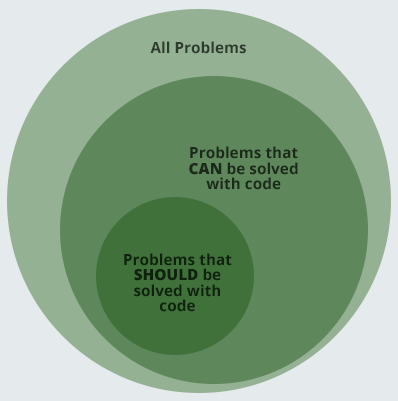
This Venn diagram shows the total space of problems that we encounter day-to-day (orange). The green is the ones that code is the right answer to. The red is problems that you can solve with code but you really shouldn’t. As Lemmy put it - ”just ‘cos you got the power, that don’t mean you got the right”! The rest of the space is problems that must be solved by non-code means.
There are all sorts of ways of solving our problems. Here are a few examples:
- In code
- At the database layer
- In operations - e.g. adding more hardware, switching our service providers
- Communication - some problems can be solved simply by talking
- Writing a quick and dirty one-off script
- Outsourcing to a dedicated service or company
Holistic system thinking is about, as a member of an organisation, being able to think about how that problem can be solved in as many ways as possible, and taking into consideration every aspect of the product, the customer, the infrastructure and so forth.
How we apply holistic system thinking
Thinking outside of code
A lot of problems can be solved without “doing any work”. For example, if a customer comes to us with a requirement, we don’t immediately go into “heads down, writing code” mode. There are often other solutions - as a tech company, you are hired for your expertise. Sometimes, it’s simply a training issue, or perhaps there is a workaround that can save months of work. The temptation to write code for everything is one that plagues all of us, but it’s rarely the only solution.
Holistic system thinking allows us to say things like “we don’t necessarily need to fix this performance issue in code. That could take us days. We can simply add more nodes in EC2 for the time being for a few dollars a day”. That’s not to say that is always the right approach, but it’s important to look at each problem and try to assess the approximate cost of addressing it head-on and whether there are other ways of resolving it.
Some problems can be solved with a quick-and-dirty one off script. Others need a carefully architected system. Knowing the difference is very difficult, there are no hard and fast rules, but at least having the option to think about the whole system, the hardware it runs on, and the client you are serving gives you a lot more options! This can make you faster, leaner and more profitable.
Asking for ... help?!
Never be too proud to ask for help. That is in no way a weakness! In this age of service oriented architectures, outsourcing to specialist services can be a massive time saver, and can result in more secure and stable solutions. Furthermore, it is often prudent to bring in a consultant for short periods. A long period with a consultant can create unhealthy dependencies, but in the short term, it can give a project a great boost.
Principle 2: No Silos
A silo is the way of thinking that says “this is my little bit, I’m responsible for just this little bit”. Silos are destructive; they lead to territorial behaviour, break down team cohesion, and in extreme cases, can slow development to an absolute crawl. One of the main concepts of DevOps is to break down the “wall” between devs and operations - so it’s no longer about developers “throwing code over the wall” to be deployed by systems administrators. We take it further than that - for us, it’s also about breaking down walls between dev, marketing and graphic design - as many roles as possible.
KPIs (Key Performance Indicators) are one of the very worst causes of silos, be very careful if you’re using them. They can cause people to focus on a narrow objective to the huge detriment of the organisation at large. In fact, my personal opinion is that they are utterly poisonous, although perhaps I go too far in this.
How we apply no silos
There are a few facets of our workflow that I will highlight to show how we use the principle of no silos.
Pull request workflow
Our pull request workflow helps us to share information. It gives the following benefits:
- A second set of eyes. I’ve lost count of the number of times I’ve solved a problem, and somebody has reviewed it and pointed out a subtle flaw, or perhaps a way I could solve it more elegantly. This results in a much cleaner codebase.
- Knowledge sharing. Say Alice writes a feature, and Bob reviews it. This means that Bob has at least SOME idea of what Alice’s feature does and how it works. Should Alice be vapourised by marauding space pirates, the cost to the business is slightly less.
- Less ego in programming. I have to be egoless, and accept the feedback of my peers. One’s natural inclination to take feedback as criticism can be set aside, and this is healthy.
Anyone can deploy
One of the main silos can be a “release person” who has to do the release every time. This can cause changes to stack up. We prefer to have the approach that no-one should be afraid to trigger a deployment and it should be easy. We should have confidence in our code as it has gone through so many feedback loops before it can get near production (tying in to automate away the drudgery and rapid, useful feedback).
Regular communication
We want everyone on our team to share knowledge. We hold daily standup meetings and exchange ideas and questions.
Writing documentation
Documentation is absolutely a deliverable. This comes in the form of working code and tests first and foremost, but a “runbook” style README.md that tells you how to, for example, install, start, and stop an application, and where the logs are, is incredibly useful. Common gotchas should be listed in there also. Any time anyone asks me a question, that’s generally a prompt for me to document something.
Principle 3: Rapid, useful feedback
We want to know about problems before our customer does. We want as few problems as possible to make it into production, and if a problem DOES reach production, we want to have the right telemetry in place to be able to diagnose it rapidly.
We adopt a ‘defense in depth’ approach - each phase of our workflow has feedback built into it.
How we apply rapid, useful feedback
Automated feedback
On our local workspaces, we write code and tests and implement features. This is the tight feedback loop that Kent Beck describes in his book “Test-Driven Development”. Once we’re happy with our work, we push it up to a feature branch.
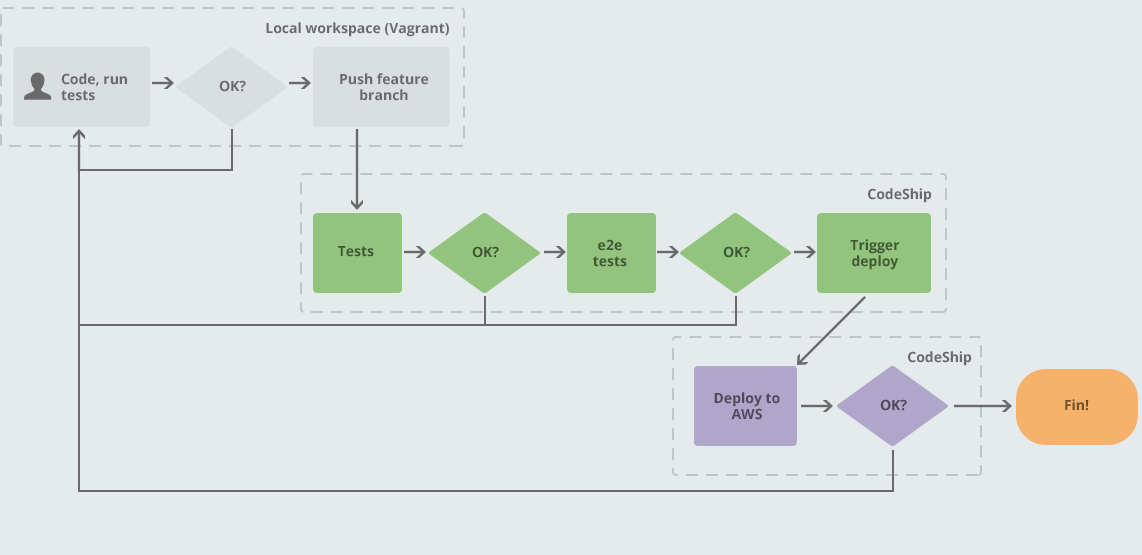
The feature branch is automatically tested with all the unit and integration tests, plus static analysis and whatever other tools we are using. If all that passes, then end to end (e2e) tests are run. If these are OK, then a deployment is triggered to a shared dev workspace that can be tested. We have an in-house tool called StationMaster which provides a list of these workspaces and when they were updated, as well as allowing us to remove stale branches.
At this point, it’s been tested by all our automation (tying into automate away drudgery) and it’s ready for manual testing!
Manual feedback
Here is our manual feedback loop:
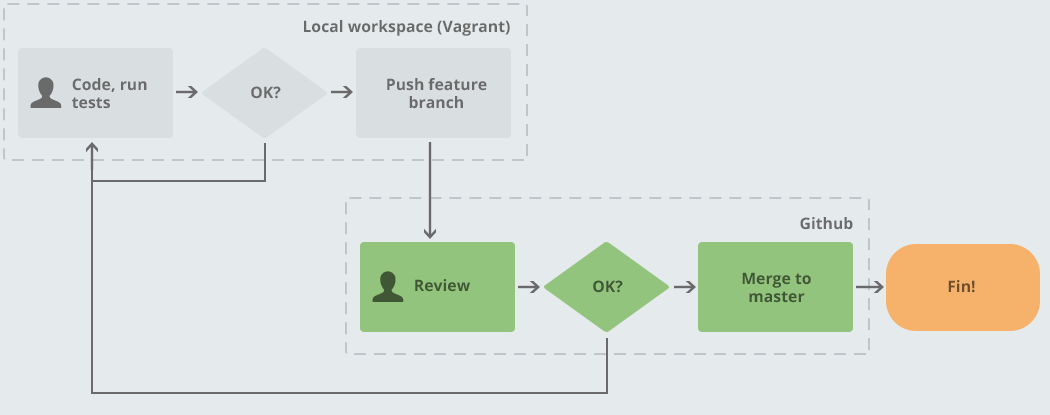
This loop only kicks in if all the automation has passed; we don’t waste our time reviewing anything that hasn’t passed our tests already. The shared branch that is deployed via StationMaster can be clicked through to straight away by the person reviewing the pull request. This ties closely into no silos as it shares knowledge and improves our confidence in our work. See my blog post about how we do pull requests for more information on this.
The merge to master operation is simply clicking the pull request merge button once the reviewer is happy. This automatically deploys to staging. At this point, the features are shown to the customer, giving us even more useful feedback! If it’s OK in staging, the feature can be merged to production and out it goes into the wild!
Feedback from beyond production
So that takes us up to production - however, once our code is “in the wild”, we still need to know what’s going on! We need to know things like:
- How is the application performing?
- Are errors being thrown?
- Are any nodes down?
The idea is that we get rapid and useful feedback beyond our development cycle. We use all sorts of tools to gain telemetry on our applications, including:
- Log aggregation. If you’ve ever had to go log diving, you’ll know what a nightmare it can be if your app scales across multiple nodes. We use Papertrail to aggregate logs from multiple web servers in a nice, searchable web interface.
- Server monitoring. You never want your customer to be the one telling you there are performance problems! We have monitoring running on all our nodes. We use Pingdom, NewRelic and the AWS alerting service.
- Stack trace reporting. If there is a code level bug, you want to know about it before your customer does. We use NewRelic for this.
The tools you use may be different; we re-evaluate our tools all the time. It’s the principle of getting rapid, useful feedback that is important!
Non-technical feedback
How are we working as a team? Is our strategy effective? Are we making good use of our time? These are all useful questions to ask. We hold regular sprint planning and retrospectives as well as discussion meetings on company strategy.
Principle 4: Automate drudgery away
I often describe this as “constructive laziness”, which is a cheeky way of saying that our time is precious - it’s vital that we do not squander it! Humans are very good at innovation, problem solving and creativity. Conversely, we are utterly dreadful at drudging, repetitive, tedious tasks. Therefore, automation is key!
We’ve talked about getting rapid useful feedback and you may have noticed that there is a lot of automation. Tools are great, but the important thing is that we are not doing anything manually that we can automate - our brains are amazing things but they are not machines. It’s best to use our time to solve interesting problems and be creative, rather than grinding through things like deployments.
How we automate drudgery away
Representative environments throughout our pipeline
It’s really important that, when developing a system, our development environments are as representative of the production environment as possible. Therefore, we provision all our development environments using the very same Ansible playbook that provisions our test, feature demo, staging and production environments. Therefore, at every stage of the pipeline, there’s one less thing that can go wrong - one less chance for the the “it works on my machine!” bomb to go off!
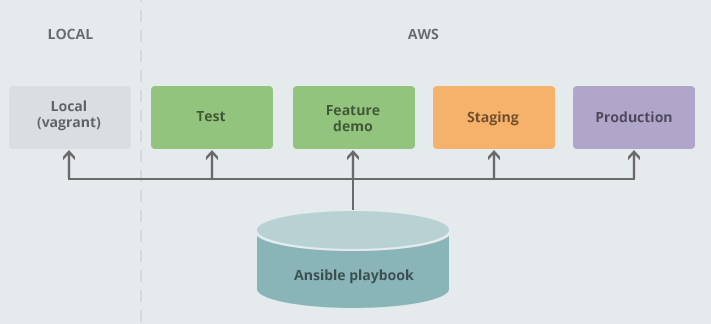
This diagram shows some of the environments we would typically use on a project, and shows that they are all provisioned identically. This allows us to have confidence that the application we produce will behave the same on production as on our local dev environment. This ties closely into holistic system thinking.
Workflow
Here is a diagram summarizing some of our automation:
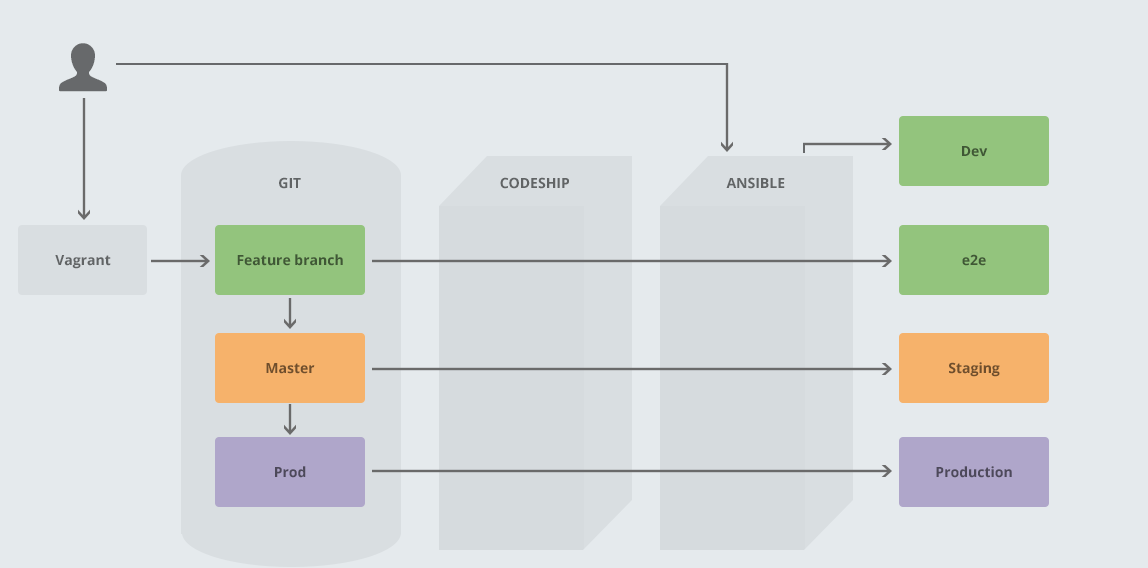
Notice that CodeShip uses Ansible to automatically provision environments and run tests, static analysis and run deployments. It’s all set up so that we use the most standard tools that we can, to try to keep it as open and transparent as possible (tying into no silos). Much of the feedback we talked about earlier comes to us through automation. Our process for standing up new nodes is automated. This frees us up to work on more interesting problems!
Our advice
You may have noticed that all our principles relate to one another; there’s a huge amount of overlap:
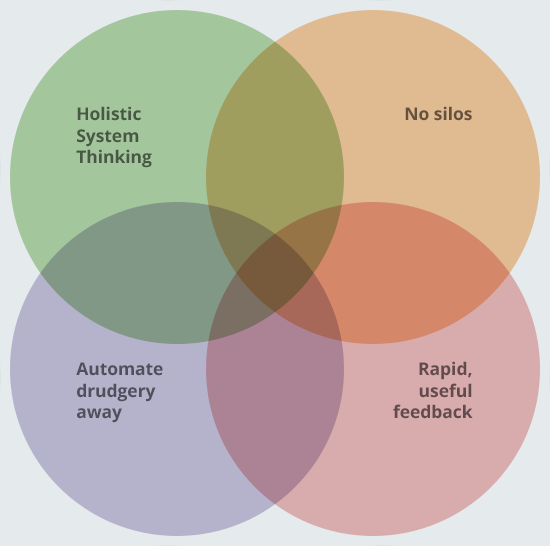
It’s all part of one picture; whilst we love technology, we are not “technology driven”, in that it’s not about the tools - the tools are an implementation detail. It’s about what you want to achieve, and what your values are. Figure out what’s important to your organisation - we suggest you work from principles rather than “we need to use Ansible” or whatever. This way, you can always improve, always move forward, and you don’t become narrow and entrenched.
Once you’ve got your principles - in effect, your vision for the organisation - implement goals step-by-step; you don’t have to do it all overnight. If you’re operating from principles, rather than strictly defined regiments, you can be flexible and try things, see what works. It’s about reducing the cost of failure, and more than that, it’s about failing as fast as possible, identifying what isn’t working, and improving.
Want help with your organisation’s operations? Got a vision that you don’t know how to carry out? Get in touch with us!
