
What would you want to read?
At Radify, we use a whole battery of automation to test our work. This is great and it helps us to keep our quality high. It’s not the whole story, though - manual feedback is just as vital as automated feedback! As such, pull requests are a really useful part of our workflow.
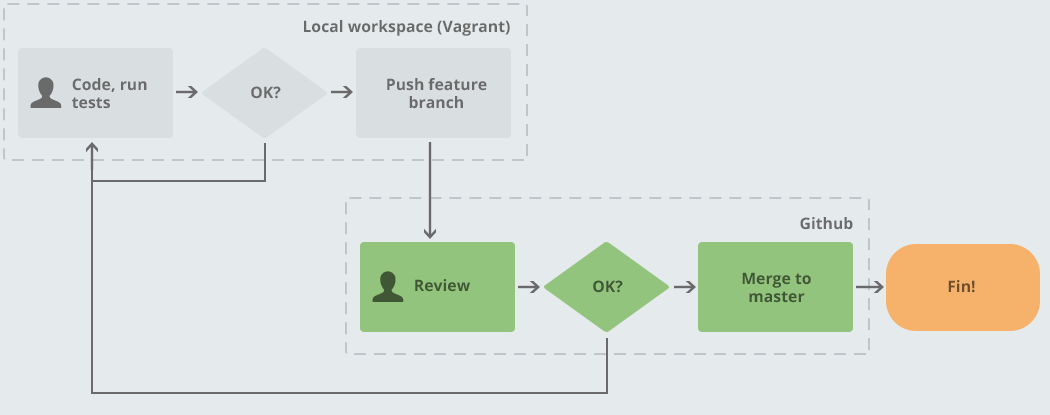
This diagram shows how we operate. A developer writes a feature, and pushes it to a feature branch, which is automatically deployed to a dev URL for testing (more on this in a subsequent post). Another developer reviews and merges this code.
This is nothing new, of course, and lots of companies adopt this paradigm, because it gives the following benefits:
- A second set of eyes. I’ve lost count of the number of times I’ve solved a problem, and somebody has reviewed it and pointed out a subtle flaw, or perhaps a way I could solve it more elegantly. This results in a much cleaner codebase.
- Knowledge sharing. Say Alice writes a feature, and Bob reviews it. This means that Bob has at least SOME idea of what Alice’s feature does and how it works. Should Alice be vapourised by marauding space pirates, the cost to the business is slightly less.
- Less ego in programming. I have to be egoless, and accept the feedback of my peers. One’s natural inclination to take feedback as criticism can be set aside, and this is healthy.
Writing a good pull request
So, what makes a GOOD pull request? Well, the way I think about it is; “what would I want to know if I were reviewing someone else’s pull request?”. Here are what I think the characteristics of a good pull request are:
1. Includes unit/integration tests
Tests show the code executing. Submitting a pull request with no unit tests does not demonstrate how the code has been used, or how the developer is thinking. Unit tests are a whole
2. References a ticket
A pull request must, in some way, link to your issue tracker. There should pretty much always be a ticket that you attach your work to. This gives you increased visibility in your workflow. You should use a commit message format like:
[#187412] Implement the flux capacitor
* Add the Y shaped shiny thing
* Tests demonstrating hooking the shiny thing into the drivey thing
In this instance, [#187412] is our issue tracker number. Most issue trackers like Pivotal or Jira can hook into Github to update tickets automatically, so your work is visible to your team and even to your customers; they can see “hey, Amy has finished the flux capacitor story and it’s ready for review”.
You might also wish to use microformats in your commit message!
3. Is neatly squashed into a single commit
If it’s only you working on branch by yourself, then consider squashing before committing. A tidy history is much easier to work with than sporadic features, it has the following benefits:
- All the changes for a single feature are grouped together
- A commit can be reverted wholesale if there’s a problem, rather than piecemeal
- Much easier to search history
It’s seldom a good idea to rebase a shared branch, but on your own branches, be hygienic and squash things!
4. Is not created until all automated tests pass
A pull request should only be submitted once a feature has passed your static analysis, unit tests, end to end tests and whatever else you have in your pipeline.
5. Has a comprehensive description
As well as having automated tests, a good pull request should list the steps to test a feature. I generally use the following format:
Title: [#4321521] Implement the territories interface
# Description
* Add an interface for maintaining territories
* Tests for territories interface and model updates
# Dependencies
* Relies upon myotherproject/pulls/42
# Screenshots
(screenshots go here)
# Test script
* Log into http://4321521-territories-interface.dev.ourcompany.com using admin credentials
* Click on ‘admin’
* Click on ‘territories’
* Make sure you can remove a territory, and that this causes an XHR that deletes the territory from the API
* Make sure you can add a new territory, verify in the database
* Make sure you can edit a territory, verify in the database
* Check that you can’t create a blank territory
Firstly, we have a description. This is likely to be taken from your commit that you’ve squashed down to.
Then, dependencies is a list of any other pull requests this one relies upon - for example, you may have separate projects for your API, UI and provisioning scripts, so cross- reference them here to prevent things from getting out of sync.
Screenshots are optional but they give people an at-a-glance visual - often, if things look dreadful, or something is clearly wrong, it saves a lot of time if the reviewer can see that from a screenshot.
Finally, I include a test script. You might have user stories that already have acceptance criteria; if that’s the case, then simply link to them. Sometimes, though, you don’t have that, so it’s really helpful if you show your test script here. Think of it this way - if you’re trying to review someone else’s work in a part of the system that you know nothing about, would you even know how to test it? It can save time and confusion to list steps here.
For example...
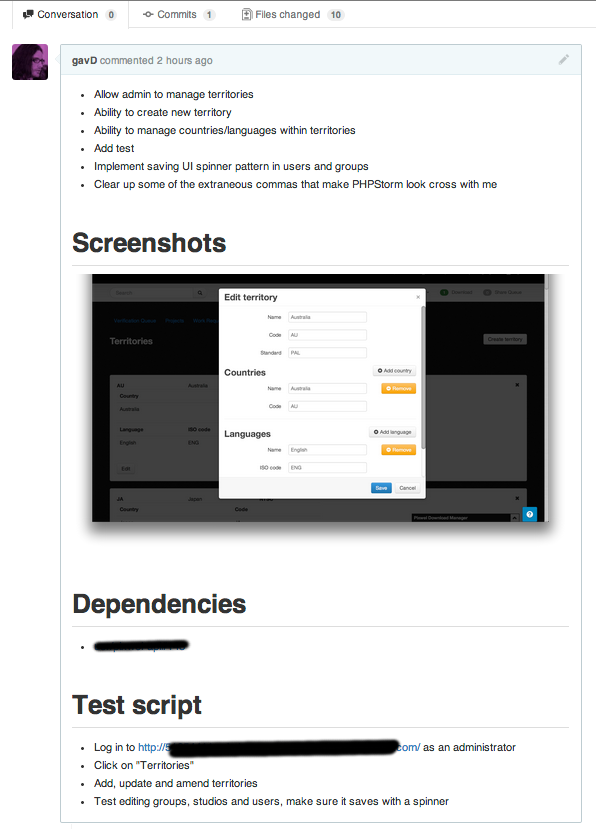
Get your coat...
So, that’s how I think when I construct a pull request - “in the reviewer’s shoes, what would I want to know?”. Sometimes this can be a bit over the top but generally it takes me less than two minutes to craft my pull request. I think that it can save my colleagues a lot of time if I structure it in this way.
So, what do you think? Do you use a pull request workflow? What kind of information do you include in yours?
