

Any update to a production system is a potential disaster. No matter how hard we try to make things absolutely perfect, errors in production can occur. So, when a problem does occur, what should we do?
In this document, I define a regression as “a bug that was introduced by a commit” and we will use this term for any problem in production that was caused by a code change.
It’s all gone wrong!
So you’re maintaining a system for a client. You’re doing continuous deployment. You’re using immutable infrastructure. You’re using feature branches to demo features and it’s all going well. Until one day, your monitoring system (or, worse still, your client! See our post "4 Principles of DevOps" for info on avoiding your clients being the ones to report bugs) sends you a message “production is down!” Your blood runs cold — what do you do?
A cursory examination suggests that the problem corresponds to a recent deployment (New Relic, for example, allows you to mark deployments, which is very useful for diagnosing bugs in production). We need to pull the latest code off, and fast!
We can basically do one of two things when such a regression occurs:
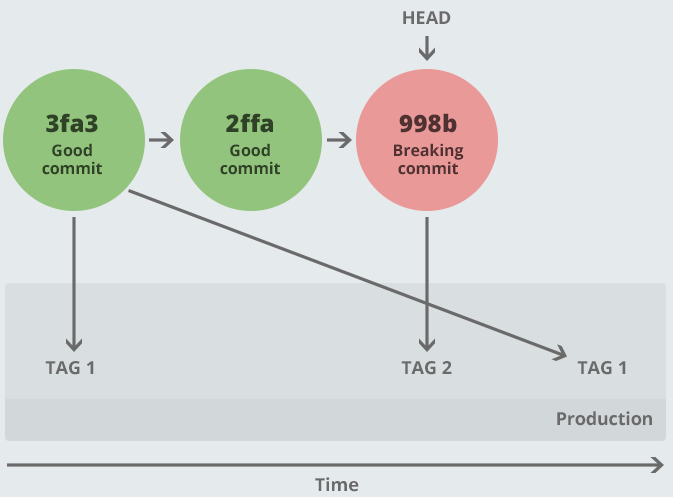
Option 1: Rolling back
When the dreaded production bug occurs, you can simply tell your Continuous Deployment system to push out an old version. Therefore, you’re pushing out the last known good tag.
What’s wrong with option 1?
It might seem good at first, but pushing out an old version creates several problems:
- The system state is not the same as HEAD.
- People can come along and deploy by committing to production, thereby re-breaking it without realising.
- There is a reliance upon person-to-person communication, and everyone is busy and it’s easy to miss things even if we are diligent.
- Requires additional automation - you would require some kind of “deploy old tag” functionality outside your existing deployment mechanism.
Option 2: Forward-only
Create a reverse merge, commit it, tag it and push it:
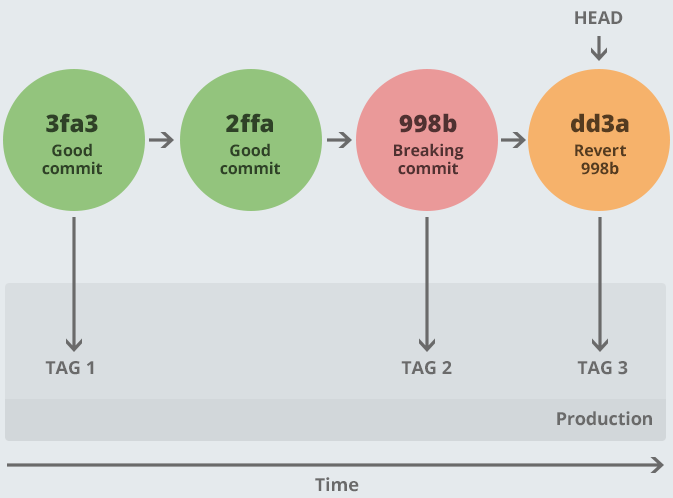
So, instead of putting an old tag onto production, we have created an additional commit (dd3a) which reverts the breaking commit (998b). This means that we are only ever going forwards. We are only ever using the release tool to push releases. Nothing “magic” is happening.
Why am I recommending option 2?
Forward-only means that you’re only deploying whatever is the latest version. It can’t get out of sync. Advantages:
- HEAD and deployed code are not out of sync.
- Lower risk of rolling out bad code accidentally. In option 1, you could end up continuing to develop against a broken HEAD.
- Code is in a working state in the repo as well as on the production environment.
- Does not break your existing automation - you don’t need a “special case” to push old tags.
- Works particularly well with immutable infrastructure
Wrapping up
We advocate forward-only deployments for the reasons mentioned above. Obviously, this is for critical production problems only. It’s the simplest, fastest way of getting production back into a working state without compromising repository, automation and development integrity. Of course, you still have to find and fix your problem and re-integrate the changes from the breaking commit, but that’s a separate issue! The purpose of this article is simply to define a strategy to buy you some time while you get things sorted properly.
Do you agree or disagree with our strategy? How do you manage production bugs?

