
A legacy project is any project that you or your team did not create. It might have been left to you by another organisation, or it could have been brought in as part of a competitor buy-out.
Many legacy projects are still in use because they are robust, they do the job, and they are mature. There are, however, many common challenges that come with maintaining or developing on a legacy system. We all have to deal with these challenges at least some of the time.
Risks of Legacy Projects
The risks in legacy projects include:
Poor comprehension. When we take on a project, we take on its conceptual model and programming paradigm, which may be alien to us. Even if it follows patterns we are familiar with, there will be design decisions and technical debt of which we are unaware.
Stale dependencies. Many legacy projects use deprecated frameworks or languages.
Lack of tests. The most common problem with legacy systems is lack of tests.
Most legacy systems I have worked with have exhibited these risks. In the worst case, I had to deal with code that was over a decade old with no documentation, had no tests, was built in an archaic language, and did not even have a build script to compile it!
Thankfully, there are strategies for dealing with these kinds of projects. This article will focus on one of those strategies: using characterisation tests.
First, though, let us take a moment to consider the nature of change in software so as to have context for our objectives.
The Nature of Software Change
There are two sources of change to software: intended and unintended change.
Intended change is deliberate. It is intentional, such as a bug fix or new feature that did not break anything. Unintended change is mistakes, misunderstandings and side effects.
To avoid unintended, haphazard change, we need to manage change - we can’t make a set of alterations to an unknown product and expect it to work. As software professionals, we have a responsibility to make sure that all change to the system is intended change.
Characteristics of Change
Here we identify characteristics that change should and should not have:
Should be
- Intentional - deliberate change that has the effect that it is supposed to.
- Atomic - discrete alterations which affect one thing only. Has no side effects. See our blog post "perfect pull requests" for related information.
Should not be
- Haphazard - poorly thought out, ad-hoc, and unstructured.
- Side effect-y - change that does not affect only one part of the system, but has unintended side-effects elsewhere in the product.
By asserting that change matches our desired criteria, we begin to stabilise our understanding of our legacy project. One mechanism to help us to achieve this is characterisation tests.
Characterisation Tests
Michael Feathers defines characterisation tests as "tests that characterize the actual behavior of a piece of code". A characterisation test is likely to use similar or even the same tools as unit tests. They are similar to unit tests, except that they are only the what, not the why - they snapshot what a piece of code does, but do not necessarily represent any kind of understanding of the system under test.
They are used for detecting unintended change:
Producing Characterisation Tests
There are two ways to produce a characterisation test. Firstly, they can be produced manually using a unit test tool. I recommend choosing something that allows you to mock and stub easily, such as Kahlan.
Secondly, characterisation tests can be generated. BlackBoxRecorder in .Net and JackBoxRecorder for Java allow a sort of "record and playback" approach.
Example Characterisation Test
Here is a very simple snippet of code:
function foo() { return "bar"; }
To characterise this function, we can write a test such as the following (which uses the excellent PHP testing tool, Kahlan):
describe("foo()", function() {
it("returns bar", function() {
expect(foo())->toEqual("bar");
});
});
Now, if foo() changes in any way, we will know about it (as all characterisation tests should run on commit, as per our article 4 Principles of DevOps).
Characterisation Test Workflow
When a commit is made, all tests are run. We then make a decision on whether that change was what was intended based on our "managing change" criteria as defined earlier.
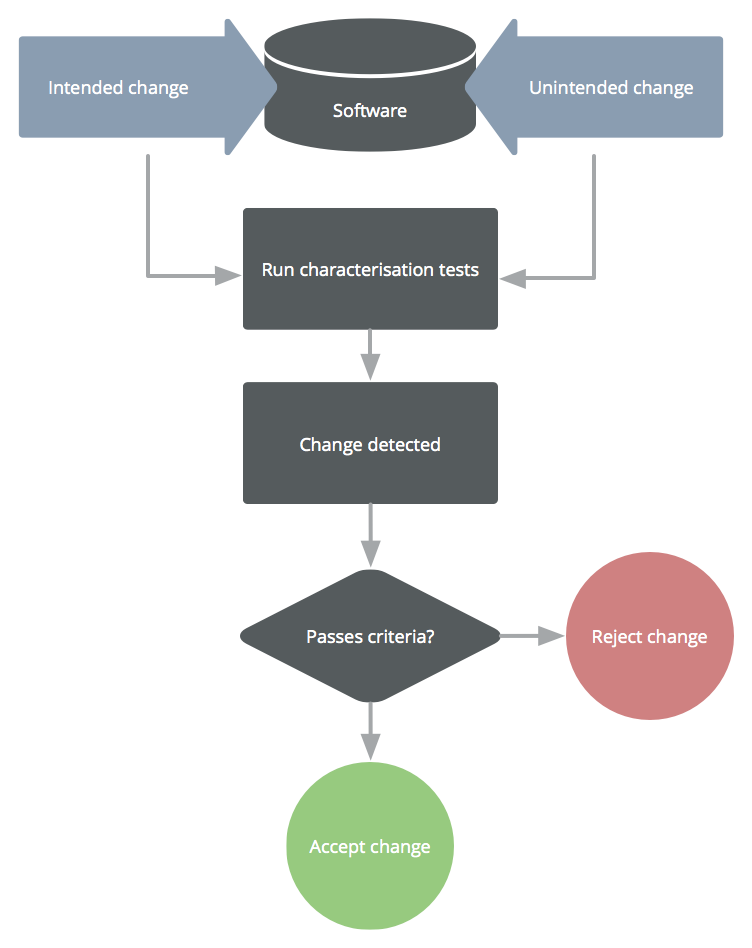
We do this by checking the change against our criteria. Is the change intentional and atomic? Is it free of side effects? Our characterisation tests help us to establish this by failing if something is no longer doing what it used to be.
Let’s assume we have the following code:
function foo() { return "bar"; }
class ApplicationDescriber {
public static function getName() { return foo() . " app"; }
}
With the following characterisation tests:
describe("foo()", function() {
it("returns bar", function() {
expect(foo())->toEqual("bar");
});
});
describe("ApplicationDescriber", function() {
describe("getName()", function() {
it("returns the name of the application", function() {
expect(ApplicationDescriber::getName())->toEqual("foo app");
});
});
});
Then, someone makes the following change:
function foo() { return "boop"; }
When the tests run, they will tell us:
- Before this change to
foo()foo()returned "bar", now it returns "boop"- Class
ApplicationDescribermethodgetName()used to return "bar app", now returns "boop app"
Not only did the change to function foo() trip its own test, it also tripped the characterisation test for class ApplicationDescriber! This has exposed a coupling in the system - changes to foo() affect function getName() in class ApplicationDescriber. At this point, we would step back and examine this change against the criteria we defined earlier:
- Was it an intention of this change to affect the application name from
ApplicationDescriber::getName()? - Should the system be refactored to decouple these components?
This is, of course, a very simple and contrived example, but it serves to illustrate the practical usage of characterisation tests.
Lifecycle
Here is the lifecycle of a characterisation test in 4 phases:
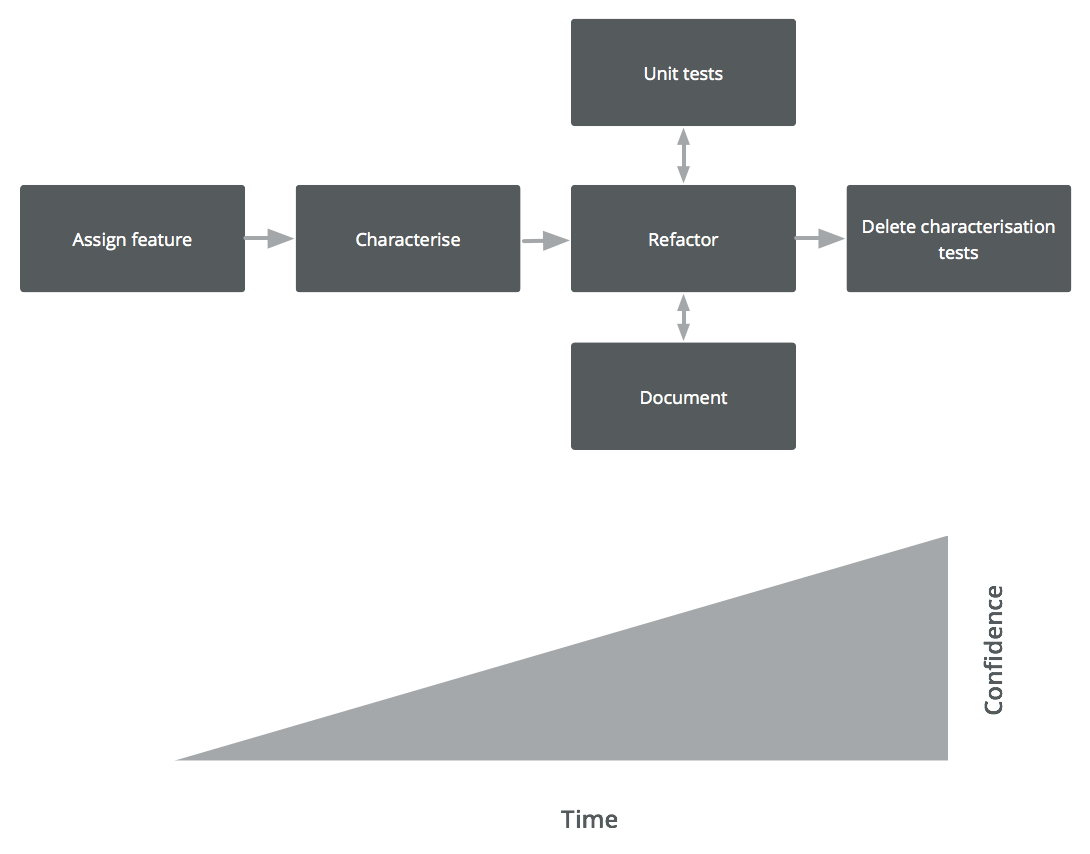
Phase 1: Panic
Let’s say we are assigned a feature to work on. We start off with no knowledge of the feature and minimal confidence.
Phase 2: Characterisation
We characterise this feature. Characterisation increases our confidence because, if a change happens, we will know about it, but it does not necessarily increase our understanding.
Phase 3: Understanding
Just because we have characterised something doesn’t mean we’ve understood it. We therefore refactor and write proper tests. Our understanding can now develop from a position of stability, helping to ensure that change is intentional.
Phase 4: Confidence
Once we are comfortable with our tests and documentation, we can throw away our characterisation tests. We don’t need them any more - there’s no need for this safety net because characterisation tests have no context. Semantically they don’t mean much; they are just a snapshot that we can now move past.
Why throw characterisation tests away?
They are only useful when you have low confidence and low test coverage. As confidence and test coverage grow, characterisation tests can actually become a drag on your velocity. Let’s illustrate this with an example.
You have two controllers that both use a DateParser. You then either write or generate characterisation tests for your project. You now have a characterisation test for each.
Let’s say you make a change to the date parser.
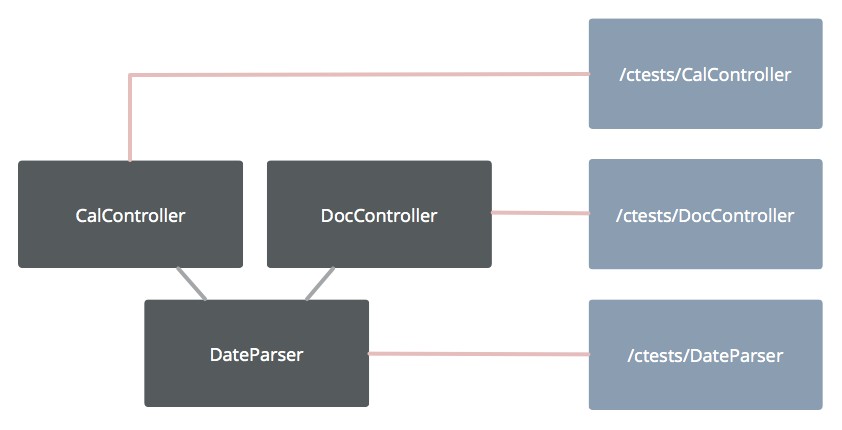
A change to the date parser might well invalidate all three tests, tripping three alarms! Of course, this depends on a lot of variables, such as how well factored the project is and how well written the tests are. Regardless, you can start to get false positives. When we start getting false positives in tests, people lose confidence. Therefore, these characterisation tests are now stale.
When is a characterisation test stale?
A characterisation test is stale when you have unit tests around the same region of code. Remember that characterisation tests are not based on an understanding of a system - they simply describe what it does right now. Once you have unit tests which reflect an actual understanding of the system, throw away the characterisation tests as they are now exerting drag rather than adding value.
Strategy for Using Characterisation Tests
1. Don’t change until you have tests around the code
Without tests, you risk making unintentional changes.
2. Delete when they become stale
False positives cause people to lose confidence in tests, so throw away characterisation tests after they are made redundant by unit/integration tests.
3. Separate out characterisation tests
Do not mix in characterisation tests with your unit tests; instead, put them in a separate directory. Characterisation tests are not based on an understanding of the system; they are more like a snapshot of the application’s functionality, so they should not be mingled in with more mature tests.
4. Make increasing test coverage a deliverable
There is always pressure to produce features, which can result in perceived pressure to skip testing. This is a totally false economy; if change is not managed, side effects can cause a legacy application to crumble in a matter of weeks. Instead, make increasing test coverage an achievable, trackable sprint deliverable - for example, "increase test coverage by 1% this sprint".
5. Be aware of the broader picture
Characterisation tests must not be all you use to stabilise your legacy projects. Rather, they are a part of a broader picture of stabilisation. Here are some complementary strategies, all with the goal of stabilisation:
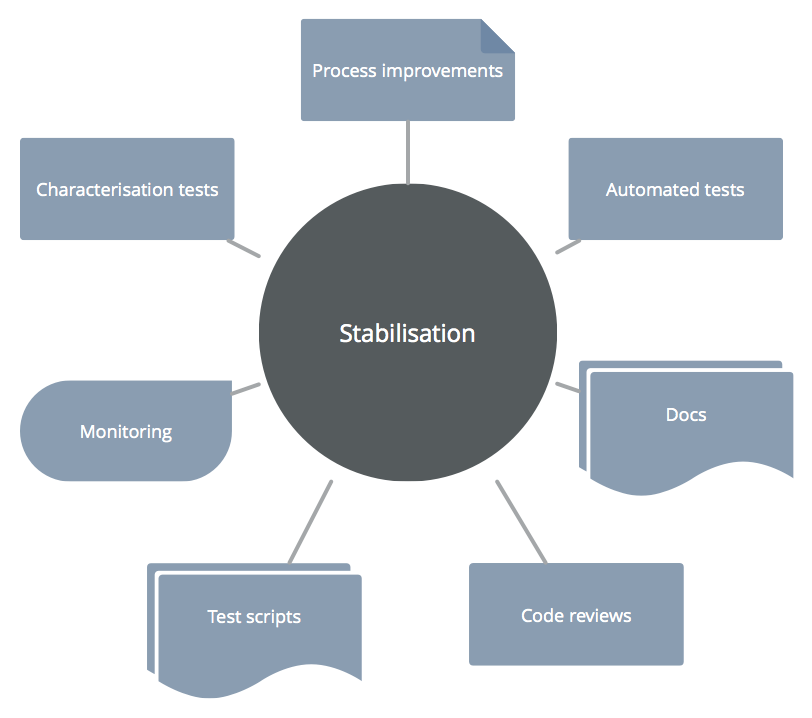
Wrapping Up
Taking on a legacy application can be fraught with peril, and it is vital to ensure stability as quickly as possible. We, as testing professionals, have a responsibility to make sure that all change to the system is intended change. Characterisation tests are a great stepping stone towards assuring that change to a legacy application is intentional and atomic, rather than haphazard and unpredictable.
