
Recently, Mark posted an article about recovering from a failed relationship. This got me thinking that a certain amount of failure should perhaps be expected as part of doing business - not least because failure can be incredibly instructive.
I've made some great mistakes in my time. In my first job, I accidentally emailed some classic Gothic fiction to a large number of customers. Thankfully, I was not subjected to the fate as Poe's protagonists, but I've never forgotten the sweaty palmed terror as the realisation gradually dawned on me that I had failed to check the "test mode" box...
At conferences and meetups, in blog posts and tweets, successes are shouted. Perhaps there is something of a cult of competence. Most of us are obsessed with appearing hyper-competent, but really, we are not paid to be right all the time - we are paid to build value. Naturally, all organisations want to look as competent as possible, but the truth is that every individual makes mistakes, and no process can prevent them all. As organisations are made up of people, it follows that every organisation makes mistakes.
In a 2012 talk entitled "the loneliness of the long distance coder", Carey Hiles admitted to some priceless blunders. Four years on from that talk, I still hear people talk about how it was encouraging to hear someone admit to mistakes. Similarly, Craig and I occasionally talk about screw ups on the Never Out of Beta podcast, and the feedback from our listeners has been that it's good to hear experienced engineers talk as candidly as possible about their weaknesses.
If taking ownership of our fallibility can be encouraging to our peers, can there also be benefits to our organisations? Perhaps even benefits to our clients?
Prevention of and elegant recovery from failure
Pretending we are perfect as an organisation is fooling no-one, least of all ourselves. Accepting occasional failure as part of doing business enables us to be proactive on three fronts:
1. Reduce the likelihood of failure
We learn, grow and improve over time to make a better class of mistake. That is, instead of making "novice errors" with wide consequences, we make more sophisticated clangers that have fewer ramifications. A more experienced engineer, for example, will partition work in such a way that a failure in one module will not disable an entire system. The novice, having experienced fewer errors, may not think in such terms. The experienced engineer will still have problems, but they are of a better class - no longer the sweepingly disastrous bumblings of the neophyte.
2. Reduce the cost of failure
As part of accepting that failures occur, it is wise to make it easier to recover from problems. This can include technical aspects such as having a disaster recovery (DR) strategy, continuous deployment, and rolling backups. The non-technical side is even more important - you should also have good, honest, genuinely respectful relationships with your clients. Think about your relationships with your family - some of the same things that allow you to recover from arguments with your family - respect, trust - come into play when a deployment goes wrong and you have to tell the client.
3. Respond proactively to failure
This may sound cliched, but try treating a mistake as a lesson - it's an opportunity to improve your process, tooling or knowledge. The very fact that a failure has occurred demonstrates room for improvement.
Going public? Boundaries in response to failure
Sometimes, we can derive general instructions from a specific failure and publish those in the form of secondary deliverables. This is not something to be taken lightly, however - whilst we believe that we shouldn't shovel all our errors under the carpet, it's naive to think that we should broadcast every mistake.
Once we have resolved an issue, there are 3 sets of people that we may inform:
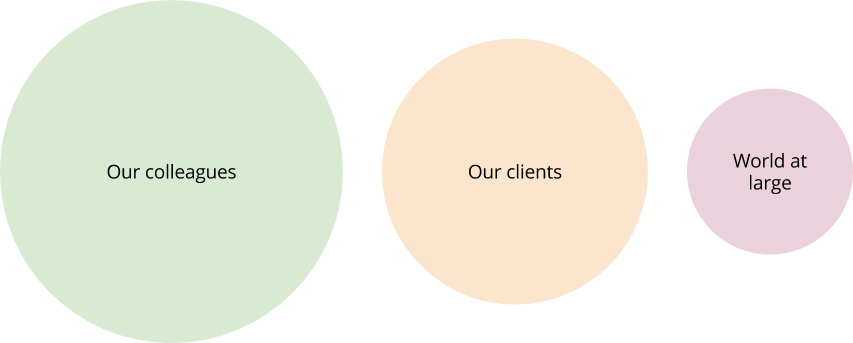
We should generally inform the first set, our colleagues, of most non-trivial problems - there are certain problems that can be resolved internally and need go no further. This is where an organisation does a lot of its learning and growing. Agile retrospectives are just one example of how this may be applied.
The second set of people, clients, should not be bombarded with every triviality, but if an incident seriously affected them, it is worth discussing with them how it can be prevented and whether things can be improved. Discussion of mistakes with clients should:
- Be honest
- Be timely (otherwise trust becomes eroded)
- Be accompanied with a strategy to prevent the issue in future
- Give them options, but leave them in charge
From the client's perspective, they should see our organisations respond proactively and professionally. This can actually improve trust and help us to work together with our clients: psychologically speaking, occasional failures, if recovered from professionally, actually improve the perception of an organisation.
Our first responsibility is to our clients and we must never leave them exposed; we should never disclose anything that can harm our client's reputation, business or security. If we can anonymise an incident, we may, with a client's consent, consider "go public" to our third set of people - the world at large - with some lessons learned from the problem. This diagram defines a potential flow for responding to a failure and maximising benefit without exposing a client:
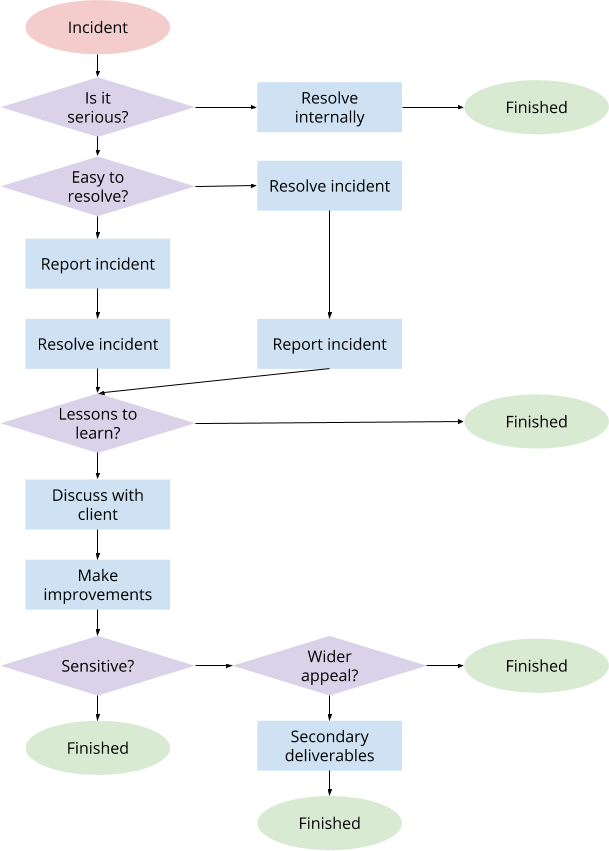
Anything you "go public" with must be anonymised and must not give away any of the client's information
Is there an optimal failure rate?
We've suggested that occasional failures can help us to reassess our processes, tools and skills and demonstrate our ability to react, change and improve. If, however, we make mistakes frequently, are simply incompetent and do not benefit. If, however, we never make mistakes at all, perhaps we are stagnant and in a false sense of security. Perhaps there is such a thing as an optimal failure rate:
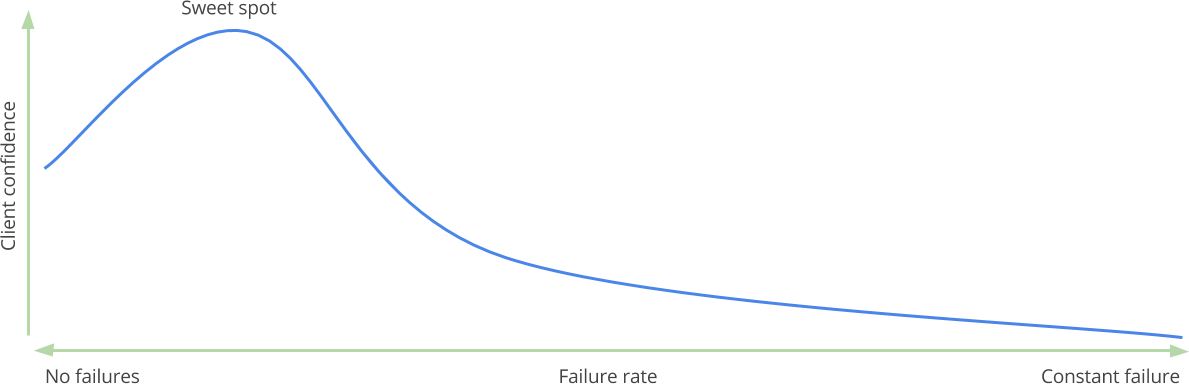
This hypothetical sweet spot could be expressed as "things rarely go wrong, but when they do, the organisation responds very quickly," a state of affairs which inspires maximum confidence in clients.
Failures can be classified into two camps:
- "True" failures that affect your customers and their customers
- Failures caught by process and automation
The latter category of failures prevented from ever manifesting "in the wild" by processes, practises and automation you have designed to avoid "true" failures.
The ratio of these failures can be compared to an Optimal Failure Ratio (OFR). This allows us to accept the potential for future failure and continually improve guards to protect our colleagues, clients and the world at large from ever having to experience them.
The reason why ratio is better than rate is because rate is just a indicator, ratio is a measure against something else. If you can't measure you're relegated to being only an observer. Failure rate is interesting, while ratio is actionable.
Wrapping up
All organisations and individuals make mistakes, but we can use them to learn, improve and build trust. There are even advantages to occasional failures, provided we respond to them professionally and do not exceed the Optimal Failure Ratio (OFR). We can also derive some useful secondary deliverables using lessons learned from failures.
